优化DeepSeek-R1性能:NVIDIA Blackwell GPU突破延迟极限
本文将探讨 NVIDIA TensorRT-LLM 如何基于 8 个 NVIDIA Blackwell GPU 的配置,打破 DeepSeek-R1 在最小延迟场景中的性能纪录:在 GTC 2025 前将 67 token / 秒 (TPS) 的速度提升至 253 TPS(提速 3.7 倍),而目前这一速度已达 368 TPS(提速 5.5 倍)。
实现配置
一、工作负载配置文件
输入序列长度 (ISL):1000 token
输出序列长度 (OSL):2000 token
二、模型架构
DeepSeek-R1 的基础主模型包含:3 个密集层(初始)和 58 个 MoE 层,此外还有 1 个多 token 预测 (Multi-Tokens Prediction, MTP) 层(相当于 MoE 架构)用于推测性解码。我们的优化配置将 MTP 层扩展成 3 个层,采用自回归方法探索其最大性能。
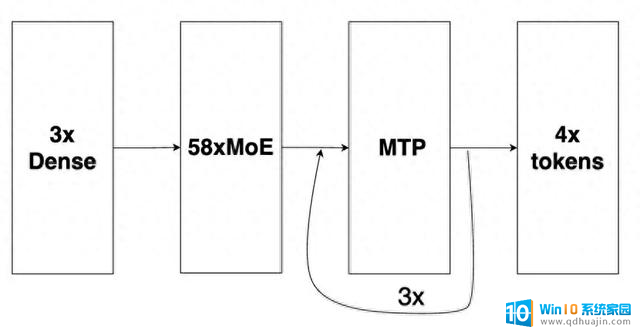
图1: DeepSeek-R1 的基础主模型
该图片来源于 Github: Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA Blackwell GPUs 一文,若您有任何疑问或需要使用该图片。请联系该文作者
三、精度策略
我们探索出了一种能够更好平衡准确度与性能的混合精度方案。
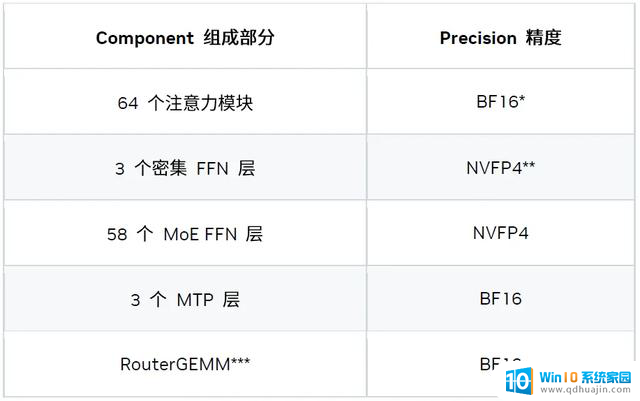
* TensorRT-LLM 已支持 FP8 Attention。但在该延迟场景下,低精度注意力计算并不能提升性能,因此我们为注意力模块选择了 BF16 精度。
** NVFP4 模型检查点由 NVIDIA TensorRT 模型优化器套件生成。
*** RouterGEMM 使用 BF16 输入 / 权重与 FP32 输出来确保数值的稳定性
四、并行策略
我们还在 8 个 Blackwell GPU 上尝试并引入了混合并行策略。具体而言,该延迟场景的最佳策略为 “TP8EP2”,其定义如下:
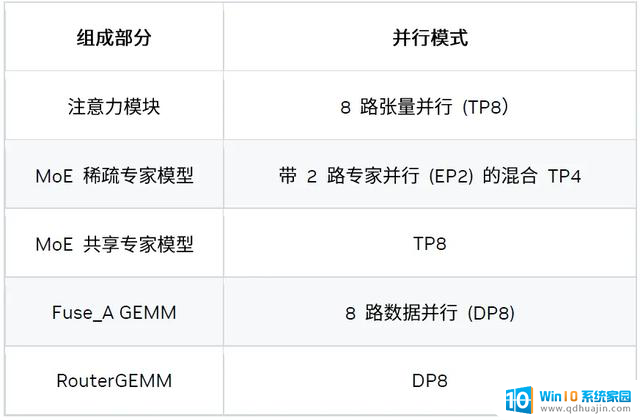
五、一图整合
现在,我们将所有内容整合成一张图,该图表示的是解码迭代中的一个 MoE 层。

该图片来源于 Github: Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA Blackwell GPUs 一文,若您有任何疑问或需要使用该图片。请联系该文作者
图中的模块包括:
主要优化

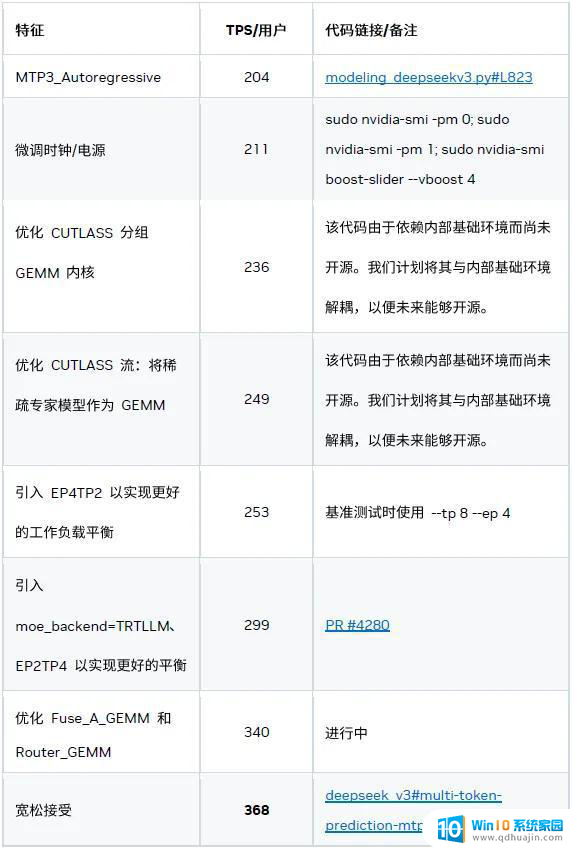
一、系统级优化
1、CUDA Graph 与可编程依赖启动
CUDA Graph 对于克服小型工作负载中的 CPU 开销必不可少,而可编程依赖启动可进一步降低内核启动延迟。
2、MTP
基于 MTP 的两种优化措施:
1) 自回归 MTP 层
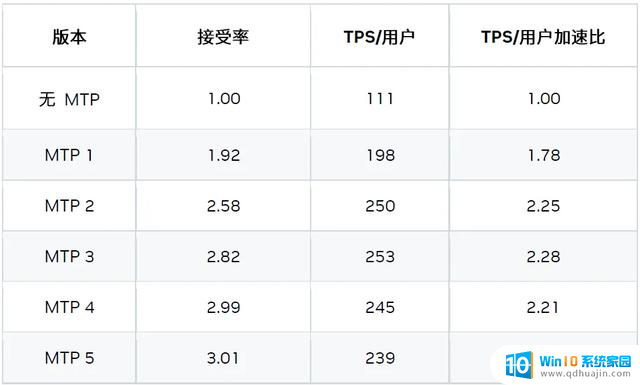
根据我们的研究结果,3x MTP 层的配置性能最佳。
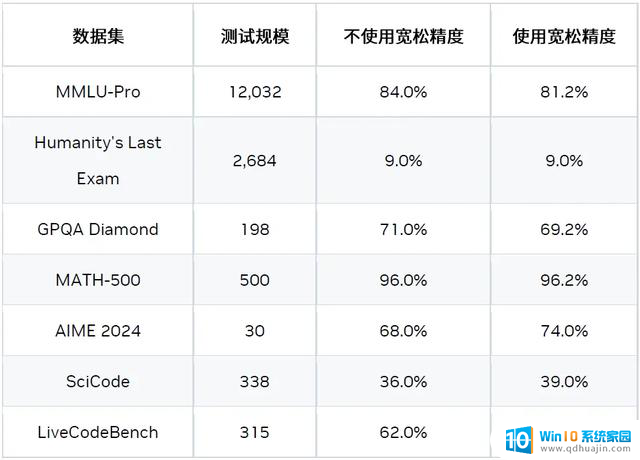
2) 宽松接受验证
逻辑推理模型 (如 DeepSeek R1) 的生成过程可以分为两个阶段:思考阶段和实际输出阶段。在思考阶段,如果启用宽松接受 (Relax Acceptance) 模式,候选 token 处于候选集时即可被接受。该候选集基于 logits topN 和概率阈值生成。
在非思考阶段,我们仍采用严格接受模式。

这是一种宽松的验证和比较方法,可以在对精度影响很小的情况下,提升接受率并带来加速。
如需了解更多信息,请访问:
multi-token-prediction-mtp
3、多流
我们引入了基于多流的优化措施以隐藏部分内核的开销,例如:
稀疏专家模型作为 GEMM (仅当 moe_backend=CUTLASS 时有效)
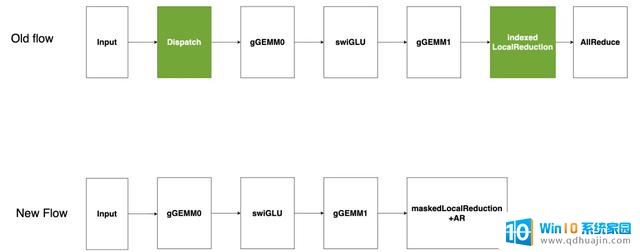
该图片来源于 Github: Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA Blackwell GPUs 一文,若您有任何疑问或需要使用该图片。请联系该文作者
现有的基于 CUTLASS 的稀疏专家模型流(如图所示)将输入的 token 分发到指定的专家模型,然后在每个专家模型的输出上进行索引式的局部归约,最后进行全局 AllReduce。分发和索引局部归约在低延迟场景下会产生高开销。为解决此问题,我们提出将“稀疏专家模型作为 GEMM”处理,即将所有 token 发送至每个激活的专家模型,并在局部归约前屏蔽不需要的输出。由于分组 GEMM 受显存限制,冗余 token 产生的额外计算开销几乎没有影响,有效避免了昂贵的分发,同时减少开销。
4、重新平衡稀疏专家模型
稀疏专家模型常用的并行化策略有两种:专家并行 (EP) 和张量并行 (TP)。专家并行 (EP) 将每个专家模型分配到独立的 GPU,以此实现高显存和计算效率。但 token 放置依赖于数据,导致 GPU 间工作负载分布不均,并在 MoE 模块后的 AllReduce 步骤中显示额外开销。张量并行 (TP) 将每个专家模型均匀划分到多个 GPU,虽平衡了工作负载,但却牺牲了数学 / 显存效率。
结合 EP / TP 的混合方法可缓解上述问题。实验结果表明,TP4EP2 配置在实际中表现最佳。
另一方案是将所有专家模型权重存储在由 4 个 GPU 组成的集群中,随后将其复制到另一个 4 GPU 集群,智能路由器可将 token 动态地分配到各集群。该设计在不显著影响本地显存和计算效率的前提下,保持了工作负载分布的平衡。
二、内核级优化
1、注意力内核
我们开发了定制的 MLA 注意力内核,以便更好地使用 GPU 资源应对延迟场景。
2、分组 GEMM
我们的默认 MoE 后端基于 CUTLASS,该后端具有灵活性和稳定性,但可能不是最佳的性能方案。
另一个 MoE 后端是 TensorRT-LLM,其性能更优。我们正在努力提高其灵活性和稳定性,未来将作为延迟场景中分组 GEMM 计算的默认后端。
3、通信内核
对于小规模消息,受常规 NCCL 延迟影响的 AllReduce 内核效率低下,为此我们开发了一款定制化的一次性 AllReduce 内核。该内核通过先模仿初始广播,然后进行局部归约的方式,利用 NVSwitch 的强大硬件能力在最小延迟场景中实现了更优的性能。
4、密集 GEMM 优化
我们重点优化两种密集 GEMM:Fuse_A_GEMM 和 RouterGEMM。因为这两种 GEMM 占据了大部分执行时间、显存效率低下且难以分片(两者均基于 DP)。
我们开发了一个定制的 Fuse_A_GEMM,通过将大部分权重预先载入到共享显存(通过 PDL 实现并与 oneshot-AllReduce 重叠),大幅提升了性能。当 num_tokens < 16 时,该内核性能较默认的 GEMM 实现有明显提升。
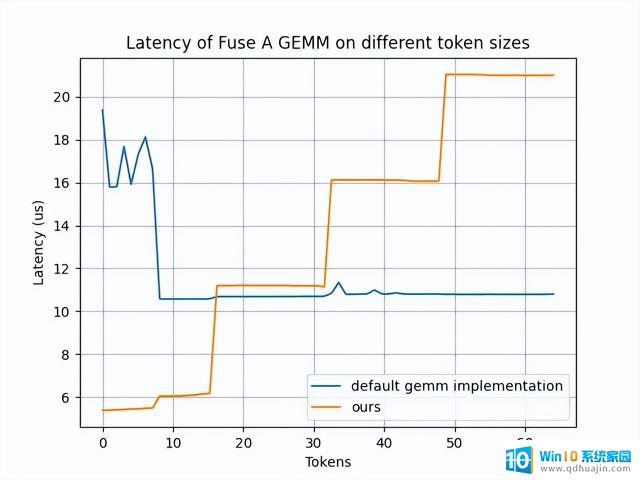
该图片来源于 Github: Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA Blackwell GPUs 一文,若您有任何疑问或需要使用该图片。请联系该文作者
我们通过使用内部的 AI 代码生成器,自动生成经过优化的 RouterGEMM 内核。在 num_tokens ≤ 30 时,该内核性能较默认的 GEMM 实现有显著提升。
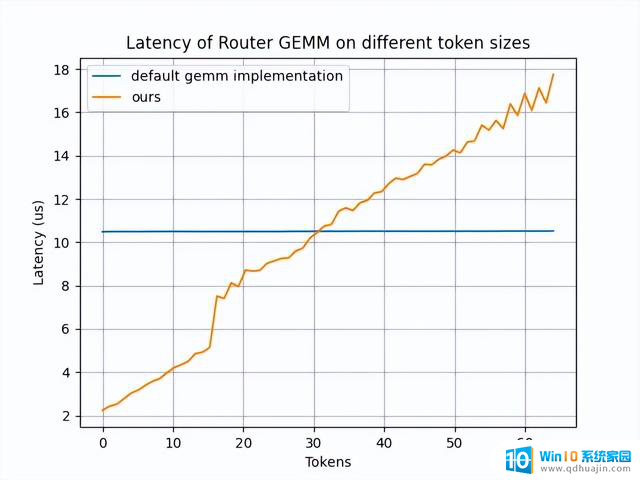
该图片来源于 Github: Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA Blackwell GPUs 一文,若您有任何疑问或需要使用该图片。请联系该文作者
5、内核融合
为了减少最小延迟场景中额外的全局显存写读开销,内核融合必不可少。我们目前支持以下融合模式:
如何复现
https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/Best_perf_practice_on_DeepSeek-R1_in_TensorRT-LLM.md#b200-min-latency
需要注意的是,宽松接受模式是 Deepseek-R1 模型的特有模式。若要启用该模式,需在准备基准数据集时设置 add_generation_prompt = True,示例代码如下:
还需在 speculative_config 中设置 use_relaxed_acceptance_for_thinking: true, relaxed_topk: 10 和 relaxed_delta: 0.6。
后续工作
结语
在延迟敏感型应用中突破 DeepSeek R1 的性能极限是一项非凡的工程。本文详细介绍的优化措施是整个 AI 技术栈各个领域的协作成果,涵盖了内核级优化、运行时增强、模型量化技术、算法改进以及系统性能分析与调优。希望本文介绍的技术和最佳实践,能够帮助开发者社区在任务关键型 LLM 推理应用中更充分地发挥 NVIDIA GPU 的性能。